Messy world outside and domain-centric design
This post describes the motivation behind software design principles like domain-driven design or layered and hexagonal architectures. The core idea is nothing new, but I strongly focus on the why, while hiding it under a pile of “story telling”. I think that this form and goal is useful because many people newly introduced to mentioned techniques struggle to appreciate their benefits while disliking apparent complication and boilerplate. If it’s you, reading this will hopefully help you to dismiss your doubts.
The article is very verbose compared to a ~simple message it tries to convey. That said, I stand behind the extensiveness of it because I think it’s important when struggling to find the incentive to follow these principles. But at the same time, I summarize the core points in a compressed form in the TL;DR section where you can skip to if you feel like giving up while reading the article or before even trying.
Table of contents
Why we build software #
I will start the article with a slightly philosophical question and that is: Why we build software anyway? I guess there are various motivations driving people to write code and build software. But a major and objective one is that we do that to solve someone’s problem.
And problems have a domain. The term (application) domain is actually quite tricky to define, but you can go read how people managed in the Wikipedia article. Instead of trying myself, I will present the concept on examples.
Let’s say that someone’s problem is to have a tasty affordable beer in a nearby pub. That’s actually what I deal with quite often. Not sure about the business potential of a hypothetical application for that, but this problem still has a domain. Possible entities and their attributes and relationships are depicted in the following picture:

A domain for “I want to have a tasty affordable beer in a nearby pub” problem.
There is a person who has certain preference for different beers. This captures the inconspicuous adjective “tasty”. We also need to know what pubs offer which beers. And to satisfy the requirement “nearby”, we need to know the location of the person and all pubs.
Now imagine a slightly different problem: Pubs need to know if some of their stored beer is going to get spoiled. This is something somebody likely built a software for already. It is somewhat related to the first problem but there are definitely differences, so let’s see a potential domain for it:
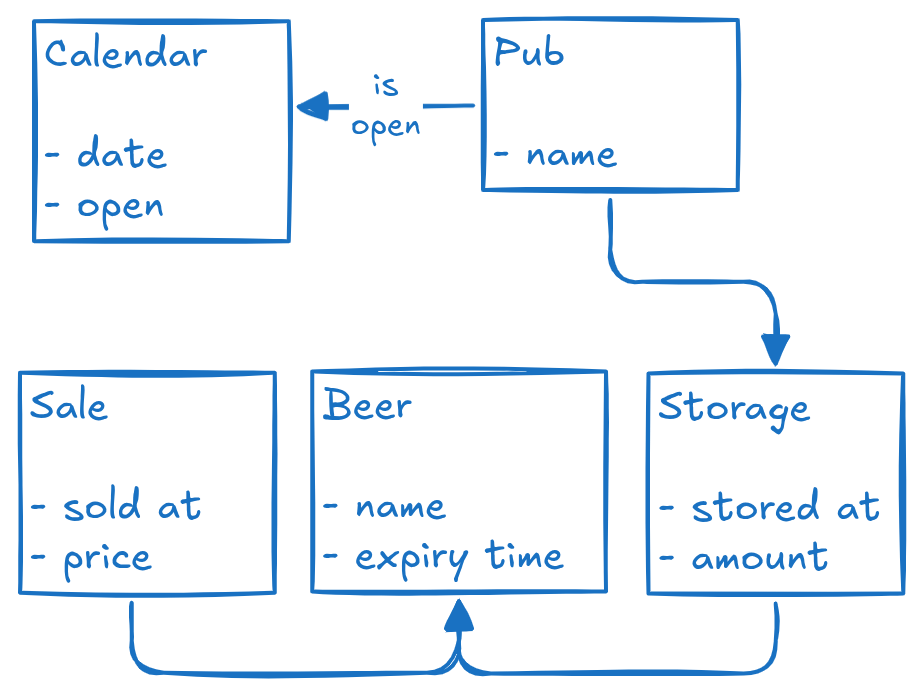
A domain for “Pubs need to predict if some of the stored beer is going to get spoiled” problem.
Again, we have pubs and beers. But instead of offering, they are connected through storage relationship. We also track the sales so that we know how much beer is left. And the concepts of calendar and when the pub is open help us make better predictions, because it’s not helpful to indicate that the beer will get spoiled when the pub is closed.
This is only an example of how to capture this domain. We could choose a different solution for the calendar entity, for example by defining opening hours as rules (Mon–Fri, 16:00–22:00) with exceptions. Or we could track how much beer is left in a different way too. This is exactly the kind of questions you ask when modeling the domain: What do we need (in our domain) to be able to solve the problem?
Problem solutions exist in the real world #
The challenge is that the problem solution exists in the real world.
It would be nice to stay inside our cave and carefully design perfect domains, but that would help no one except maybe our own ego aesthetic senses.
So we need to meet the outside reality.
And that brings some troubles, for instance
- JSON format doesn’t support a native datetime type,
- Efficient data table component for web is very difficult to implement and yet it displays a conceptually simple structure,
- Legacy systems have inappropriate APIs but you still need to use them,
- Different processors have different instruction sets even if they represent common operations like addition.
And many more, I don’t need to tell you…
The situation that we find ourselves in thus looks like this:

Perfect domain versus reality.
We have our nice and clean domain full of sunshine, rainbows and unicorns. And it’s surrounded by this messy and dangerous outside world that we need to deal with.
But it’s not time to give up. What we need to do is to build up a fence and isolate the domain and business logic from technical and implementation details.
Suddenly, the situation becomes this:

Isolate the domain and business logic from technical details.
What it allows us to do is to fully focus on designing the right domain for the problem at hand. It’s also recommended to cooperate with the subject matter experts so that you can build the shared understanding and standard vocabulary[1]It’s annoying and unnecessary cognitive load when you need to use different terms for the same concept in the code, in the team and with the customer, just because you didn’t think about the most fitting name upfront.. Since the implementation details are ignored during this phase, you can really speak the same language as the experts, without them being lost in technical jargon. More likely it will be you who is lost in the subject matter concepts.
Once the domain is designed, then it’s time to go look for appropriate technologies that fit that domain best and fulfill all requirements.
Now there is a new problem. The isolation that we introduced is nice, but we still need to interact with the outside world. Because solutions that do not are useless as they basically become something called
Schrödinger’s app is correct and buggy at the same time, you don’t know because you can’t look.
— me
To resolve this problem we need to introduce thin layers to translate gibberish of the external objects to aesthetic poetry of domain objects. The emphasis on the word “thin” is quite important. These interfaces between the outside and inside then handle the details and limitations of the chosen technology.
And we finally arrive to the final situation:
Thin interfaces between the outside and inside.
We have our perfect domain that is still isolated from the outside world. But we also have those little portals through which things enter and exit.
Common interfaces #
Now it’s the right time to turn an abstract essay into concrete terms. What are those little portals that allow the communication with the outside world? Let’s see some examples.
Repository design pattern is a great one as it can be used in virtually any context. It’s an abstraction layer over a data store, be it a database, filesystem or even other software system. It handles all intricacies of the underlying storage while providing a nice and clean CRUD API.
In server-side APIs, there are controllers[2]I was really surprised that I failed to find a good generic resource on the controllers concept that is less tied to the original definition in the MVC pattern, traditionally used for UI applications, and more focusing on its role in server-side APIs. So here is at least documentation for a few, hand-picked frameworks: NestJS, ASP.NET, Ruby on Rails, Spring Boot. for inbound requests and gateways for outbound requests. They should handle the low-level details of the communication protocol and format and interact with the domain core.
SPA frontends have the same needs. Pure UI components represent what users see, API services fetch data, global state manager (like Redux or MobX) – well – manages global state[3]You may wonder what “messy outside world” challenges are related to the global state management in SPA applications. Aren’t we free to carelessly store anything as JavaScript values and objects? Well, if you want features like persistence to local storage or time-travel debugging, then not.. With libraries like React, it requires more discipline than the framework’s guardrails to avoid mixing business logic with UI definition or letting server-fetched DTOs slip through into the domain. Sadly, it’s easy to fail at that.
Games use input managers to map raw key presses, mouse clicks, joystick movements, or any other possible kind of input, to events like jump, draw a card or pause the game. Because the game logic shouldn’t really care about which input caused the game action, only that the game action was requested.
Programming language compilers, especially if they aim to be widely-applicable, traditionally use three-stage architecture which separates the front (source language → intermediate representation), the middle (optimizations) and the back (IR → machine code) components[4]I acknowledge that compiler frontend and backend are usually anything but thin, which was my recommendation for interface layer. But it’s still worth to strive for making it as thin as constraints of the problem allow. This can be supported by generalizing the algorithms used in these components and provide way how these generalizations interact with specific implementations.. Note that procedures like register allocations have traditionally been part of the compiler backends, but it’s possible (regalloc2, TPDE) to implement it generically in the domain and only interface it with the environment (number of registers, specific constraints) which demonstrates well the core idea of this article.
In the world of embedded systems, there are various microcontrollers or other kinds of devices with specialized designs and wildly different properties and constraints. At the same time, the operations done on these devices are often common, like blinking a LED, write and read to a communication bus, or maybe something more than that. That’s where hardware abstraction layers (HALs) come in so that your embedded software can focus on the logic.
In my proof-of-concept graph library, the graph storage is hidden behind a shared interface. In theory, it could really be anything – a standard in-memory representation, a JSON file or computed on the fly. And the algorithms (the domain) only require the standard graph operations (get neighbors, add edge, etc.).
Wow, that’s a long list (although far from exhaustive). It shows that this general pattern is applicable in wide range of software contexts. It’s also worth to summarize in a picture:
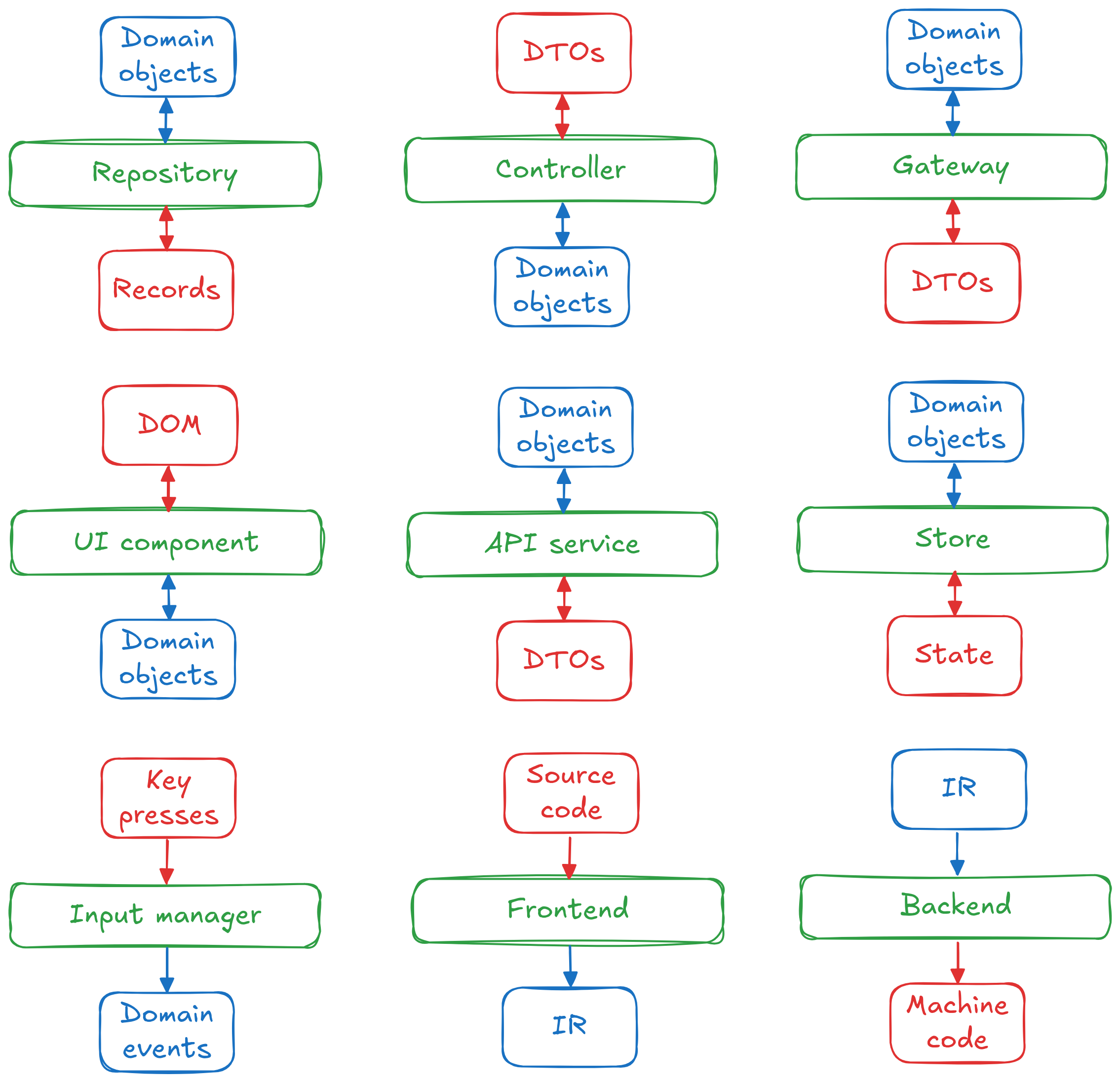
Common interfaces examples. HAL didn’t make it because it didn’t fit into 3 × 3 grid, sorry.
And now something to take away: It’s absolutely essential that the external types (red-colored in the illustration) do not cross the interface boundary. By absolutely essential, I mean highly recommended.
Focus on domain over technology #
After talking about concrete terms, I would like to get back to modeling the domain and make a case why it’s a good approach to prioritize focus on the aspects of the problem and solution instead of technical constraints[5]A fascinating read related to this is Model Once, Represent Everywhere. There it’s described how Netflix tackles the challenge that each system models core business concepts differently and in isolation without shared understanding. Their solution is to define domain models once and use these definitions to generate schemas in specific technologies for specific systems (and more). Of course, this particular solution needed for Netflix scale is not a silver bullet, but it shows how this topic is important.. I will present some code examples too and they will be in TypeScript, but it’s more or less pseudocode[6]I mean on the level of pseudocode in this context, not that every code in TypeScript is pseudocode..
Let’s revisit the examples from the very beginning of this article.
In the “I want beer” problem, we need to know the location of the user to be able to find pubs nearby. In the modeling phase, that’s all we need to care about. Once that’s clear, we can think about the technical decisions. For example, the user’s location will likely be retrieved from some GPS-based service rather than a database as people typically keep moving, at least a little.
In the “beer expiration” problem, we keep track of the dates when the beer was stored. Whether the dates will be stored as ISO strings in UTC, local time strings, numeric timestamps or even a native data type if our persistence technology supports it, we don’t care. That’s something to decide in the implementation phase.
Now let’s see another example. Imagine a scenario where we are asked to track books and their authors. Books can also reference each other. Here is a code representation of such domain:
type Author = {
name: string,
}
type Book = {
name: string,
authors: Author[],
references: Book[],
}So an author has a name and a book has a name, array of authors and array of references to other books.
The type of authors and references array are really the respective entities, not some kind of identification.
This is convenient because whenever we have a reference to a book, we can very easily get names of its references without additional indirection.
We can think of multiple implementation choices for this domain without changing it.
To persist the data, we can use
- Relational database with its concepts like primary and foreign keys and data stored in tables and columns,
- JSON file stored in a blob storage if our data won’t change at all and we don’t need optimized filtering, or
- Graph database if we realize that our application needs complicated graph operations on the “book references” relationship.
To transfer the data from a backend to a client, we can use
- JSON over HTTP which is probably the most used option nowadays,
- GraphQL if it’s clear that the client needs many different ways how to query the data, or
- Protobuf over gRPC if we expect that the data are sent only between backend services.
To display the data in a UI, we can use
- Simple table if that’s enough, or
- Temporal force-directed graph if we want to be fancy and emphasize the “book references” relationship.
These are all important decisions to make when building software. But none of these options meaningfully influenced our problem solution domain. It should be the responsibility of the interfaces to translate our domain to these technologies.
To repeat: Use the best representation for domain objects disregarding the outside world. Or at least think about it and then make compromises if needed.
Examples of better representation #
Below I collected a few code-level better/worse examples that try to communicate what I mean by that statement. They are really only examples, not meant to be followed like the universal truth. Make sure to see both variants, both code and commentary, to fully appreciate the difference. If you get tired from looking at code, feel free to skip to the end of this section.
type TemperatureUnit = "K" | "°C" | "°F";
function validate(temperatureUnit: string): TemperatureUnit {}
function requireValid(temperatureUnit: TemperatureUnit) {}The temperature unit type is constrained only to valid values and the code follows the parse don’t validate pattern[7]Specifically for TypeScript, I recommend to check the branded types technique. Other mainstream programming languages use nominal type system where we can create a new type and the typechecker makes sure that the values are really of the correct type. But TypeScript uses structural type system and branded types are needed for extra safety.. Other use cases include valid email, existing user, or objects with optional properties filled in.
function assumeValid(temperatureUnit: string) {}The validity of temperature unit is only assumed. But as you may know, not all strings are valid temperature units. Nothing prevents the call-site to pass an arbitrary string to the function and make it explode.
type Command = {
startedAt: ZonedDateTime,
elapsed: Duration,
}Specialized types (ZonedDateTime, Duration) are used to represent values with desired semantics.
These provide convenient API (e.g., convert to a different timezone or get number of milliseconds) and reduce the risk of misuse.
type Command = {
startedAt: string,
elapsedMs: number,
}Primitive value types are used for representing datetime (probably an ISO string, who knows?) and elapsed time (ok, at least the unit is in the name). This representation is likely what must be used for the JSON payload, but that should not influence the domain type.
type Temperature = {
value: number,
unit: TemperatureUnit,
}
type Measurement = {
temperature: Temperature,
}All temperature-related information is stored in one object. These two properties should always come together as knowing the value without the unit is prone to wrong assumptions.
type Measurement = {
temperatureValue: number,
temperatureUnit: string,
}All properties are inlined on the same level. This is how it might be stored in a relational database, because they use tables and columns, but again that should not influence the domain type.
type Role = {
permissions: Permission[],
}From the domain perspective, roles contain permissions, regardless what constitutes a permission. This is captured in the type.
type Role = {
permissions: string[],
}
const permissions: Map<string, Permission>;In practice, the roles and permissions could be stored in separate sources (tables in relational database or even different types of storage) and connected through some kind of identification. But this indirection is inconvenient when used in business logic.
type Overview = {
product: Product,
customer: Customer,
}Existing domain types are reused in the aggregate type. In the end, they represent specific entities in the domain model regardless of the context. It doesn’t matter that a specific use case doesn’t need all properties of those entities.
type Overview = {
productCode: string,
customerId: number,
customerName: string,
}Properties from different types are inlined (and potentially filtered) in the aggregate type.
Imagine having many of these aggregate types.
What happens if we want to change the customer ID type from number to string?
type Item = {
enabled: boolean,
}The enabled flag is a required property because it’s what business logic expects and requires.
type Item = {
// Undefined means true
enabled?: boolean,
}Maybe we introduced the enabled property later as a new feature but for backwards compatibility it is optional with some default value if not provided.
This is a leakage of implementation details (backwards compatibility) of the external API.
Moreover, having enabled? means additional, useless check everywhere it’s used in business logic.
type Operation = {
status: "active" | "successful" | "failed",
}The status is explicitly represented by all possible variants and it’s clear what each one means. It’s also possible to add more variants in the future. This is a good example why to prefer enums over booleans.
type Operation = {
completed: boolean,
successful: boolean,
}The status is implicitly built-up from multiple properties which is an unnecessary complication.
Moreover, the type allows to represent an invalid state with completed: false and successful: true.
type LangCode = "en" | "fr" | "cz";
type LocalizedText = Record<LangCode, string>;
type Message = {
title: LocalizedText,
content: LocalizedText,
}This is not an example how to do localization in an application, but it again shows a use of special type for a dedicated use case.
Whenever a support for a new language is added, the typechecker makes sure that the corresponding translations are defined for every use of LocalizedText.
type Message = {
titleEn: string,
titleFr: string,
titleCz: string,
contentEn: string,
contentFr: string,
contentCz: string,
}All languages are inlined in the message type. Whenever a support for a new language is needed, it’s up to the developer to make sure it’s added on all places. This example is a bit stretched, but subtler variants of this pattern are not rare.
Again, these examples only scratch the surface. Choosing the right representation is about practice and lessons learned.
Architectures #
After making our hands dirty with code, let’s zoom out again. I would like to match the general ideas discussed so far to specific, widely-known software architectures. Specifically, I will use layered and hexagonal architectures. There are others, like onion and clean and probably more, but for the purposes of this post the motives behind are essentially the same. I recommend reading about them after finishing my description and it should be clear what I mean.
Layered architecture is one of the most common and well-known ways to modularize an application. It separates different concerns to different layers. Typically, there is the presentation layer (UI or public API), the domain layer (domain and business logic) and the data layer (database or other persistence storage).
This is the base, but variations exist. For example, the data layer can be split into persistence (e.g., database) and infrastructure (e.g., logging or external services) layers or there is a new service or application layer providing use cases implementation on top of domain logic.
An illustration of this architecture can be seen below.
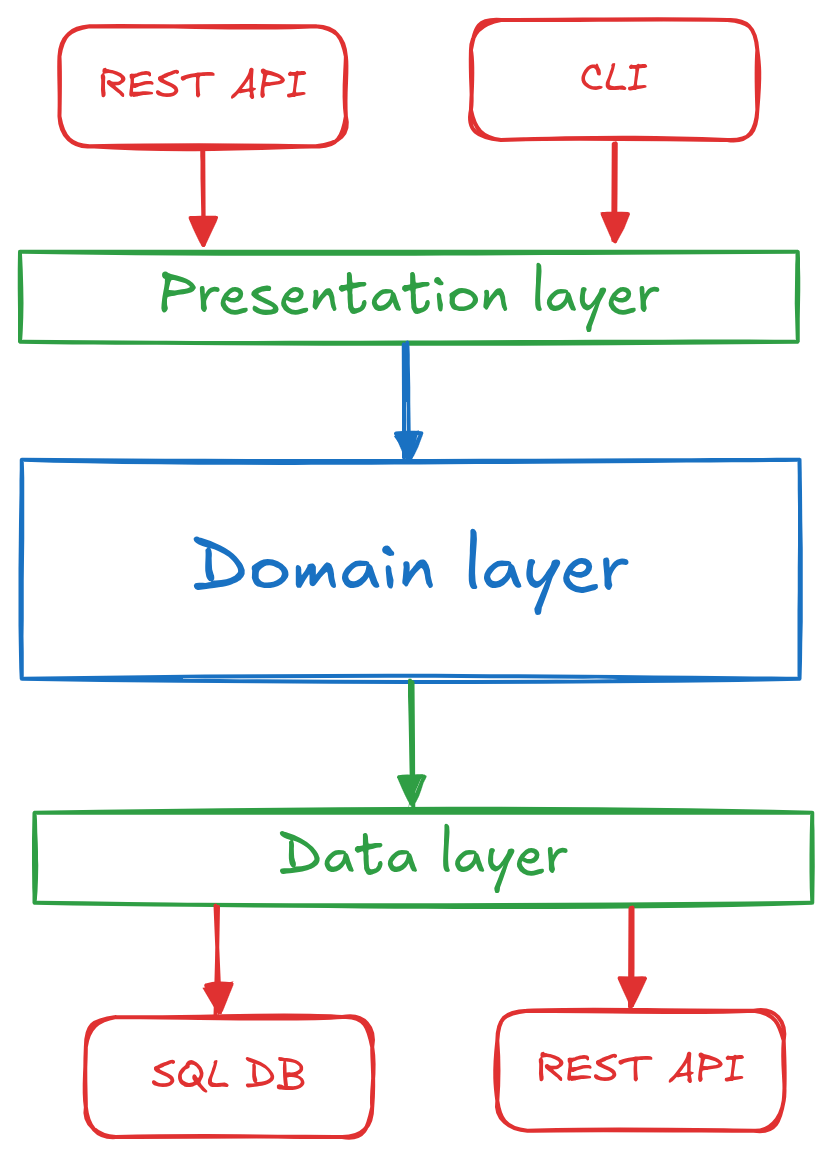
Layered architecture diagram.
Hexagonal architecture focuses on isolation and independence of domain/business logic, often referred to as core. Ports (input, data, auth, …) define interfaces to interact with the core. Adapters (REST API, SQL database, OAuth, …) implement the corresponding port interface and act as translators from and to specific technology.
The choice of ports and adapters depends on the application. Ports are a generic concept focusing on an aspect/need of the application, while adapters are concrete implementations. This distinction is important for hexagonal architecture because it argues that change or addition of a technology is not rare and the setup is prepared for that.
An illustration of this architecture can be seen below.
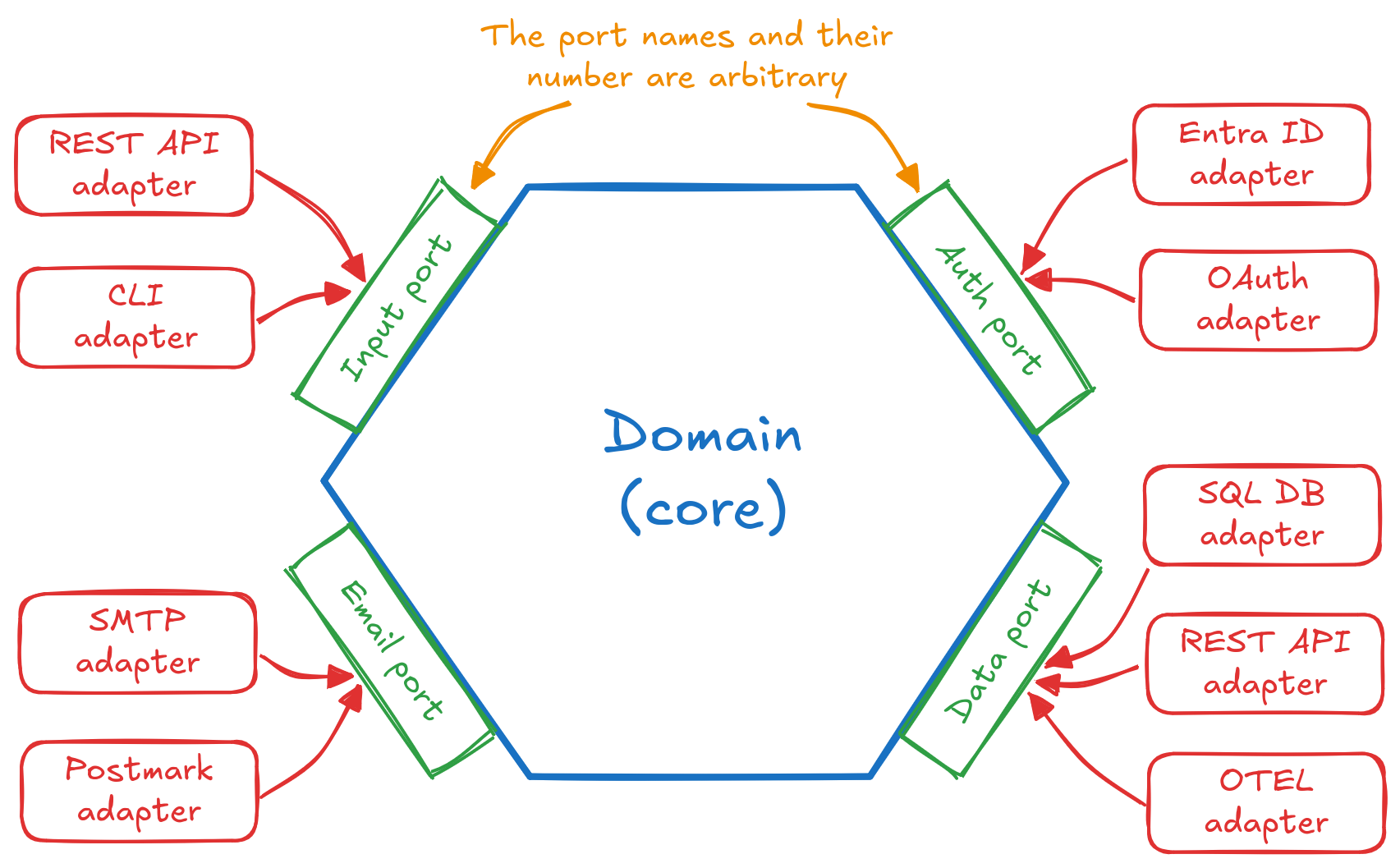
Hexagonal architecture diagram.
How these two architectures relate to the topic of this article? To answer that question, let’s compare the two in a single diagram.
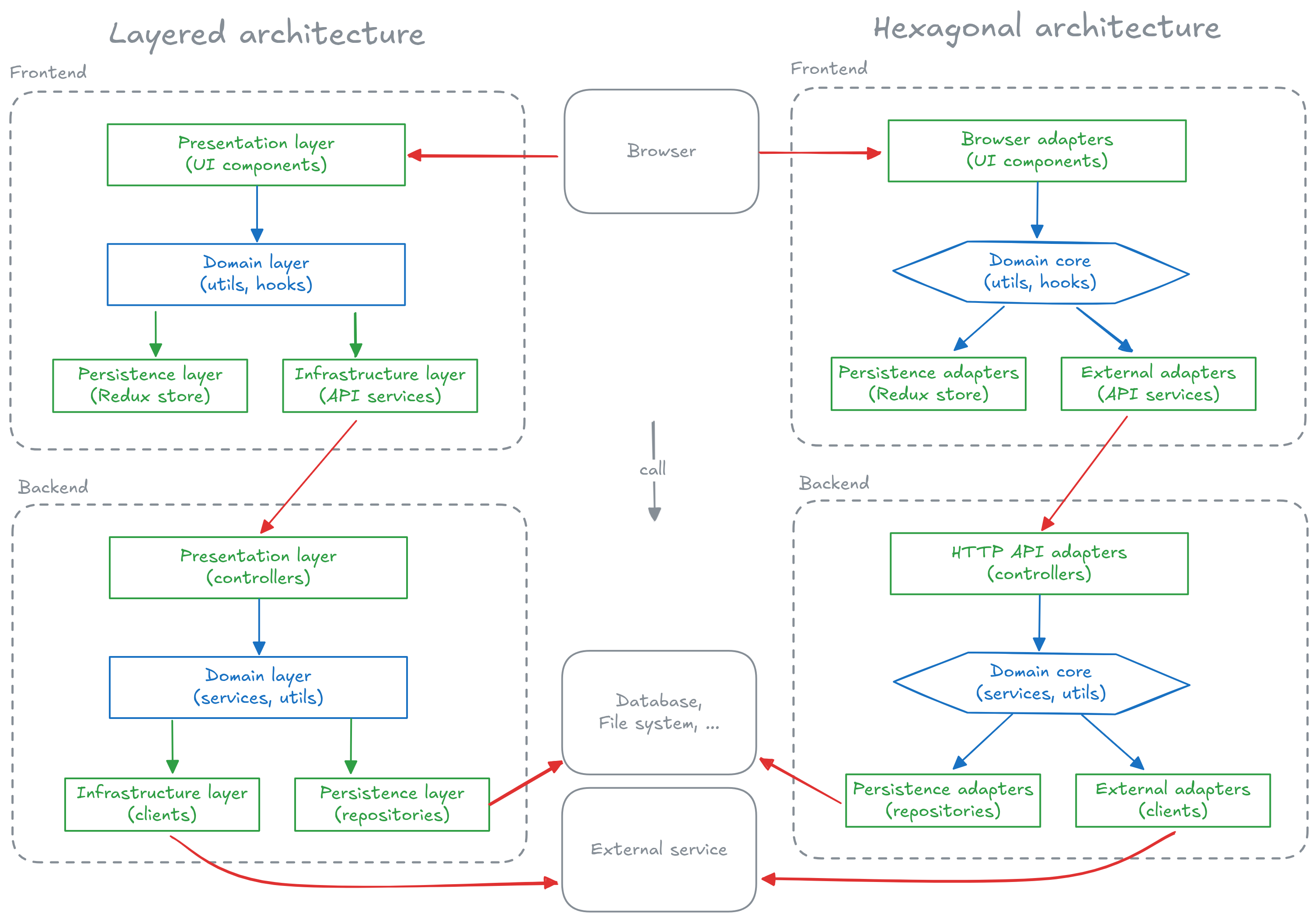
Graphical comparison of layered and hexagonal architectures.
I’m sorry, it’s a spot the difference puzzle. I hope you didn’t spend too much time with it. My point with the picture is that they are the same from the practical point of view. They both divide the application into parts concerned about different things with the goal of protecting the domain. The thesis of this post.
Of course there are differences. Otherwise it wouldn’t make sense to give them different names, right? Regarding these two, my understanding is that the main distinctions are:
- In layered architecture, dependencies go from top to bottom, that is, the domain layer depends on the data layer and “speaks its language”. In hexagonal architecture, dependencies go inwards and mapping external representation to the domain language is always the responsibility of adapters.
- The colors in my diagram are not precise. In layered architecture, the distinction between green (interfaces) and red (implementations) is not explicit. The interface and implementation live together within the layer.
As I mentioned at the beginning of this section, it’s worthy to go read the specifics of different architectures. Yes, there are details in which they differ, and these details can be important, but all of them share the core principles.
Why bother? #
This section could have been named Motivation, but it felt strange to put the motivation at the end of the article, especially when I advertised it as motivation-focused.
Even though the ideas presented here sound more or less simple, they do bring substantial effort needed to comply with them compared to the YOLO approach. And that raises questions.
Designing the domain without even touching code? Abstracting data access because I could theoretically store data in blob storage instead of database? Creating multiple types for the same entity just because working with ISO 8601 strings instead of date types is slightly less convenient?
Valid questions! And I am going to try to answer them in this section. At the same time, I think that the appreciation for these principles is directly proportional to the experienced pain accumulated while working on softwares that did not follow them. Feel free to go ahead and write code that you maintain in a way that allows you to gain this experience. And I don’t mean it sarcastically.
Ok, enough intro to this section, let’s get motivated. Why bother then?
Clean domain model boosts productivity. Implementing new features feels smooth and natural, there are no rough edges requiring finding workarounds, no subtle invariants causing annoying bugs, paradise. Of course this assumes the ideal state which is rare – or maybe even extinct – species. But isolating the implementation details of specific technologies unlocks the potential for getting closer to it.
Isolation better absorbs change. When a change in requirements comes, it usually doesn’t impact the core problem domain drastically. Maybe an entity is augmented, some entities or relationships are added, new logic is implemented or an existing one is changed.
More often, such changes affect the implementation details. Maybe displaying a thing in a different way, refactoring a table to a few new tables, creating whole new controller, supporting new gaming input device, and so on. But all these concerns are isolated in thin layers.
Additionally, the isolation reduces risks of functional regressions after technology changes (different database engine, different communication protocol, …), because these details are abstracted. And from the other side, the business logic can evolve without affecting stable public APIs.
Separation of concerns reduces the cognitive load on developers. With strict boundaries, a change in one area has limited scope of propagation and the complexity of other areas is hidden behind the interfaces. This allows to think about each area relatively independently and frees up some valuable brain capacity which would be otherwise occupied by worries about the other areas.
When you are working on the domain, you don’t need to care about how your changes are handled by respective technologies. As long as you comply with the interface, they will should.
And when your task concerns an interface layer, you can focus only on the implementation details of the corresponding technology and ignore how were incoming domain data generated or what will happen to the data you hand over to the domain.
Isolation simplifies testing of business logic by faking external world. Testing is notoriously challenging when the code under test depends on some I/O, for example databases, external systems, rendering APIs, non-deterministic components like randomness or system time, and so on. Otherwise, business logic is just code and it should be possible to run it with some inputs and assert the outputs.
When the access to I/O is isolated inside thin interfaces, it’s ready to be faked by an implementation that simulates its behavior in a predictable way without side effects. This allows exercising as much production code as feasible in tests without dealing with real infrastructure.
Clean domain model leads to better understanding by the customer. If you created the model in cooperation with the customer and focused on covering only the problem itself, it likely uses concepts very much familiar to them. It captures what they more or less have in their mind when thinking about the problem, or at least they know what you are talking about.
This is a tremendous help when discussing the project and new features. In both directions. They understand what you mean without the need for translation, and you more often than not understand them because you can map their concepts to the ones you already grasped.
Concluding remarks #
This article shouldn’t be taken as dogma. As many things, it’s about trade-offs. Maybe your software doesn’t have super complex domain and business logic and you could question if it’s worthwhile to bother. In that case, the benefits of isolation might not be that strong. But I would argue that they still hold.
The memento shouldn’t be to start spending 30 minutes contemplating how the type representing a domain entity can be perfect. But do put thoughts into it. And if you see something that will be clearly inconvenient, address that.
It’s also fine to take shortcuts. A typical example is type aliases/re-exports. Instead of writing all versions (domain, externals) of an entity, re-export one as the other. As long as they are the same and there are no inconveniences in the domain type, all is good. Once a need for divergence occurs, only then you will define them separately. But your entire codebase will be ready for this change and only relevant parts will be affected.
This post was an unnecessarily long essay on the topic of why it’s important to isolate the domain from technological details. This idea is very common in different architectures and design approaches (one of the most well-known representatives is domain-driven design[8]The title of my article uses the term “domain-centric”. That’s because I didn’t want to directly tie it to the domain-driven design approach. This approach has lot more to it, having a book and whole practice around it, whereas the scope of my essay is smaller and more general. But I don’t take credit for the term “domain-centric”, it’s floating over the internet and I just hope that it doesn’t have a specific meaning.). But when you read about them, it’s often burdened with details which are specific to that particular approach. That’s good, these details are important as guides for how to tackle problems in practice.
My goal was to demonstrate the motivation behind the core idea that is shared by all these approaches. If I convinced at least one of you, then I succeeded.
TL;DR #
We build software to solve someone’s problem and problems have a domain. Ask “what do we need to be able to solve the problem?” when modeling it.
Isolate the domain and business logic from technical and implementation details. Introduce thin layers between the domain and external world that handle the details and limitations of the chosen technology. Common interfaces include repositories, controllers, gateways, UI components, API services, state managers, or input managers. Types for external objects should not cross the interface boundary into the domain.
There are different options for data persistence, transfer, display, etc., but domain objects are (mostly) not impacted by them. Software architectures (layered, hexagonal, onion, clean, …) differ in some aspects but the goal of protecting the domain is shared.
Clean domain model boosts productivity and leads to better understanding by the customer. Isolation better absorbs change and simplifies testing of business logic by faking external world. Separation of concerns reduces the cognitive load on developers.
It’s annoying and unnecessary cognitive load when you need to use different terms for the same concept in the code, in the team and with the customer, just because you didn’t think about the most fitting name upfront. ↩︎
I was really surprised that I failed to find a good generic resource on the controllers concept that is less tied to the original definition in the MVC pattern, traditionally used for UI applications, and more focusing on its role in server-side APIs. So here is at least documentation for a few, hand-picked frameworks: NestJS, ASP.NET, Ruby on Rails, Spring Boot. ↩︎
You may wonder what “messy outside world” challenges are related to the global state management in SPA applications. Aren’t we free to carelessly store anything as JavaScript values and objects? Well, if you want features like persistence to local storage or time-travel debugging, then not. ↩︎
I acknowledge that compiler frontend and backend are usually anything but thin, which was my recommendation for interface layer. But it’s still worth to strive for making it as thin as constraints of the problem allow. This can be supported by generalizing the algorithms used in these components and provide way how these generalizations interact with specific implementations. ↩︎
A fascinating read related to this is Model Once, Represent Everywhere. There it’s described how Netflix tackles the challenge that each system models core business concepts differently and in isolation without shared understanding. Their solution is to define domain models once and use these definitions to generate schemas in specific technologies for specific systems (and more). Of course, this particular solution needed for Netflix scale is not a silver bullet, but it shows how this topic is important. ↩︎
I mean on the level of pseudocode in this context, not that every code in TypeScript is pseudocode. ↩︎
Specifically for TypeScript, I recommend to check the branded types technique. Other mainstream programming languages use nominal type system where we can create a new type and the typechecker makes sure that the values are really of the correct type. But TypeScript uses structural type system and branded types are needed for extra safety. ↩︎
The title of my article uses the term “domain-centric”. That’s because I didn’t want to directly tie it to the domain-driven design approach. This approach has lot more to it, having a book and whole practice around it, whereas the scope of my essay is smaller and more general. But I don’t take credit for the term “domain-centric”, it’s floating over the internet and I just hope that it doesn’t have a specific meaning. ↩︎